Running multiple projects in parallel with AI agents produces a counter-intuitive effect: without a compounding infrastructure, every run starts from zero. Memory stays local to the project, discovered patterns don't migrate, and cadence depends entirely on human availability. What follows describes the infrastructure that solves this problem — and why regularity is its primary condition.
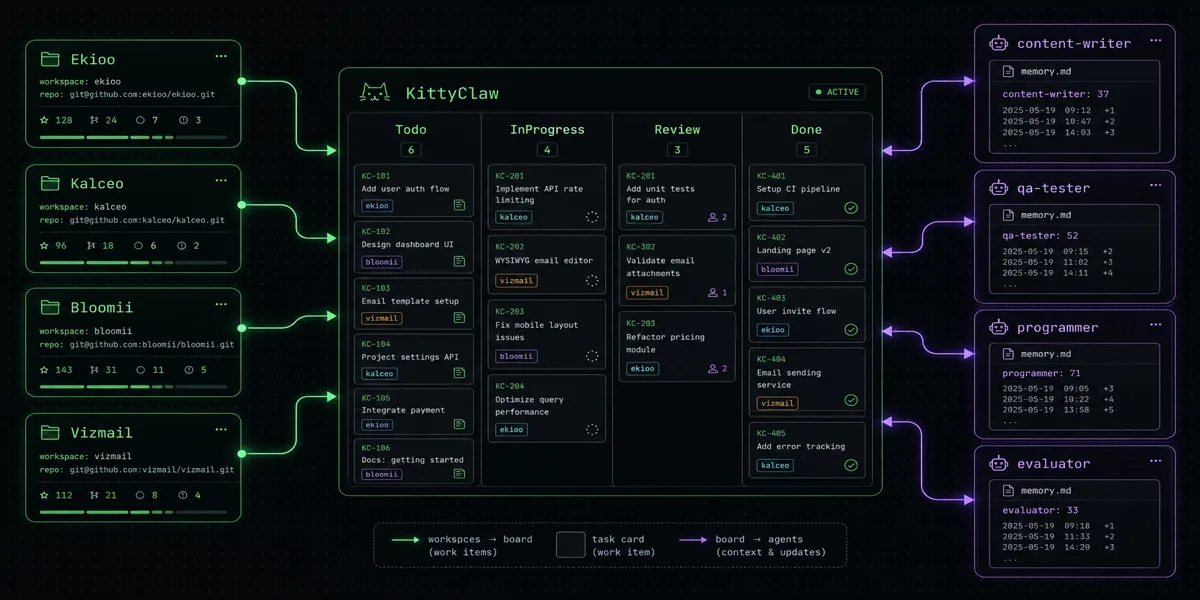
Three live projects feed this piece: Bloomii, a constructive-journalism media outlet covering social and environmental alternatives; Kalceo, a regulatory B2B SaaS for French construction contractors; and Ekioo, the agent-fleet R&D project behind this article. All three run on KittyClaw, a kanban orchestrator for AI agents.
Anatomy of an Orchestrated Project
Each project hosts a .agents/ directory with four elements:
.agents/
├── preamble.md # context injected into every agent run
├── automations.json # trigger pipelines
├── {agent}/
│ ├── SKILL.md # stable domain instructions
│ └── memory.md # accumulated learnings, run after run
preamble.md is the coherence vector. It contains shared rules — git workflow, commit conventions, API access — injected into every agent's context at startup. What lives in preamble.md doesn't need to be repeated in every SKILL.md.
automations.json defines the pipelines. The core automation, assignee-dispatch, runs three actions as soon as a ticket moves to Todo with an assignee:
{
"id": "assignee-dispatch",
"trigger": { "type": "ticketInColumn", "columns": ["Todo"] },
"conditions": [
{ "type": "assignedTo", "slugs": ["programmer", "content-writer", "qa-tester", "..."] },
{ "type": "ticketCountInColumn", "columns": ["InProgress"],
"sameAssignee": true, "operator": "==", "value": 0 }
],
"actions": [
{ "type": "moveTicketStatus", "to": "InProgress" },
{ "type": "runAgent", "agent": "{assignee}", "model": "claude-sonnet-4-6" },
{ "type": "commitAgentMemory", "agent": "{assignee}" }
]
}
The ticketCountInColumn == 0 condition prevents uncontrolled parallelism: an agent won't start a new ticket while it has one in progress. The final action, commitAgentMemory, automatically persists the agent's memory after every run — this is the key to compounding.
Memory as a Progression Tool
Where most AI agent setups remain stateless, memory.md introduces structured persistent state. Each agent maintains a file of lessons with a [+N] counter that tracks how many times each lesson has been reapplied:
## API / tooling [+5]
- curl on Windows mangles UTF-8 in JSON bodies.
Use python3 urllib.request instead. [+2]
- PR creation: gh not available;
az repos pr create has permission errors. [+2]
## SVG inline in Markdown [+3]
- NEVER use <marker> + marker-end="url(#id)" in inline SVGs. [+3]
- Draw arrowheads as explicit <polygon> elements.
The counter serves two functions: it shows which lessons have value (they recur), and it guides consolidation — when an entry reaches [5+], it migrates to SKILL.md as a stable rule. Entries at [0] are removed.
This distinction between SKILL.md (stable rules, rarely modified) and memory.md (active learnings, updated each run) is structural. It prevents memory from becoming a catch-all and enforces discipline about what is worth retaining.
Cross-Project Compounding
Agents learn from their mistakes — once an agent hits a problem, memory.md ensures it never hits the same one again. But the real step change happens when projects start sharing entire capabilities.
Shared image generation
A content-writer on Bloomii needs an illustration. A content-writer on Ekioo needs a cover. Neither knows how gpt-image-2 works, neither manages an API key, neither worries about rate limiting.
A single processor runs on a 10-minute cron in the central Workspace. Agents from any project submit a request via image-enqueue.mjs, get an ID back, and move on. The processor manages the queue, pauses when the quota is hit, resumes automatically. The agent gets notified when the image is ready.
node C:/IA/Workspace/.agents/tools/image-enqueue.mjs \
--prompt "..." --output path/to/cover.webp \
--project bloomii --ticket 189
One tool, one processor, N consumer projects. Adding a sixth project requires zero configuration — just a call to image-enqueue.mjs.
Centralized mailbox — automatic dispatch
All projects share a single mailbox, exposed through VizMail (a local HTTP server with 40+ REST endpoints). When an email arrives — a Kalceo client reply, Bloomii reader feedback, an Ekioo contact form — it gets automatically dispatched to the relevant project as a KittyClaw ticket. The appropriate agent picks it up with no human intervention.
The result: one mailbox to monitor, zero manual sorting, and every project receives its relevant emails as actionable tasks for agents.
Centralized X branding
Four projects feed a single X account (@LainAgent_AI). Each project has its own publishing tool (x-post-tweet.mjs), but the editorial strategy lives in a single file — x-strategy.md — in the central Workspace: content pillars, voice, engagement rules.
A community-manager drafts, lain approves. No audience fragmentation across four ghost accounts. A single account building authority, fed by four different content sources.
Hub-and-spoke knowledge base
The central Workspace provides shared infrastructure: API documentation (KittyClaw, Brevo, Chrome CDP), centralized credentials, CLI tools. Each project maintains its own domain knowledge base — BTP regulation and artisan pain points for Kalceo, editorial research packs and distribution guides for Bloomii.
A Kalceo agent sending a newsletter and a Bloomii agent scheduling a LinkedIn post use the same Brevo token, the same documentation, the same call patterns — without knowing the other exists. Infrastructure knowledge is written once, consumed everywhere.
Cadence as a Health Signal
Thirty to fifty tickets processed per week across all projects. That number isn't a productivity target — it's a system health indicator.
When a project's Todo column accumulates without draining, the signal is clear: the backlog is poorly prioritized, or the project lacks agents suited to the queued tasks. The weekly cadence makes this imbalance immediately visible.
The evaluator agent calculates scores after each closed ticket: first-pass success rate, feedback compliance, delivery quality. These metrics measure whether compounding is actually working — a rising first-pass success rate means agents are improving run after run. A stagnating rate signals a memory that's no longer being fed.
An agent that doesn't run regularly doesn't accumulate usable memory: it resets each time, repeats the same mistakes, asks the same clarifying questions. Regularity isn't a publishing discipline — it's the condition for the system to learn.
Conclusion
The infrastructure fits in four files per agent: preamble.md, automations.json, SKILL.md, memory.md. What makes it effective is feeding discipline: commit memory after every run (the commitAgentMemory action handles this automatically), remove entries at [0], promote lessons at [5+] to SKILL.md.
The only rule that matters: never miss two weeks in a row. One quiet week doesn't break the cadence. Two weeks break agent memory, project coherence, and the SEO signal.
Consistency first. Volume second.