Gérer plusieurs projets en parallèle avec des agents IA produit un effet contre-intuitif : sans infrastructure de capitalisation, chaque run repart à zéro. La mémoire reste locale au projet, les patterns découverts ne migrent pas, et la cadence dépend entièrement de la disponibilité humaine. Ce qui suit décrit l'infrastructure qui résout ce problème — et pourquoi la régularité en est la condition première.
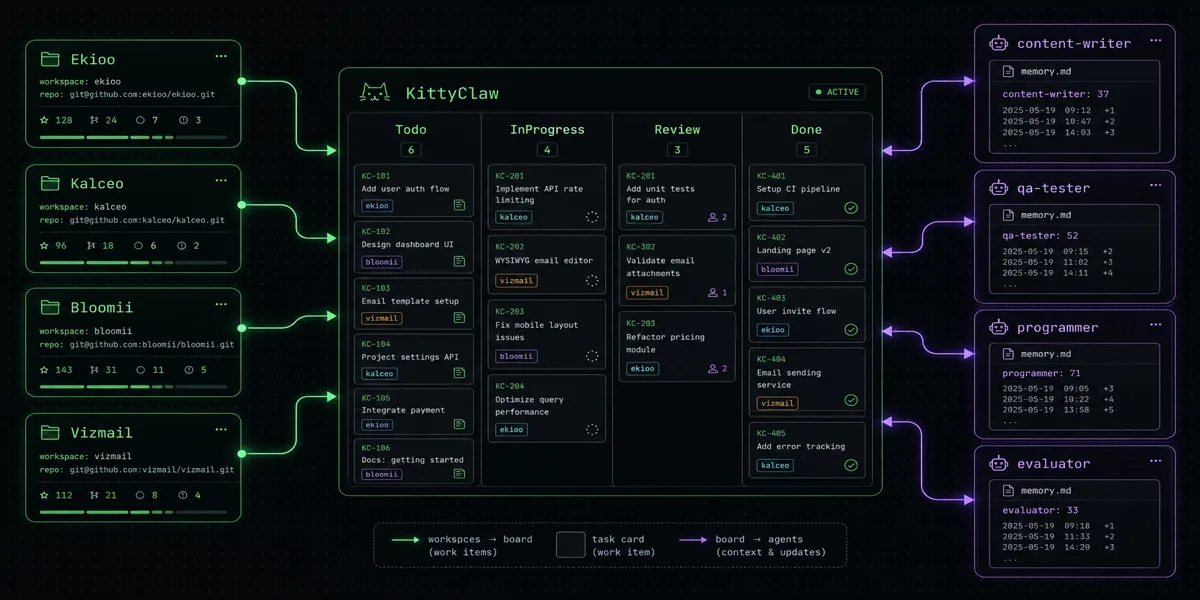
Anatomie d'un projet orchestré
Chaque projet héberge un dossier .agents/ avec quatre éléments :
.agents/
├── preamble.md # contexte injecté à chaque run d'agent
├── automations.json # pipelines de déclenchement
├── {agent}/
│ ├── SKILL.md # instructions métier stables
│ └── memory.md # apprentissages accumulés run après run
preamble.md est le vecteur de cohérence. Il contient les règles partagées — workflow git, conventions de commit, accès API — injectées dans le contexte de tout agent au démarrage. Ce qui est dans preamble.md n'a pas besoin d'être répété dans chaque SKILL.md.
automations.json définit les pipelines. L'automation centrale, assignee-dispatch, déroule trois actions dès qu'un ticket passe en Todo avec un assignee :
{
"id": "assignee-dispatch",
"trigger": { "type": "ticketInColumn", "columns": ["Todo"] },
"conditions": [
{ "type": "assignedTo", "slugs": ["programmer", "content-writer", "qa-tester", "..."] },
{ "type": "ticketCountInColumn", "columns": ["InProgress"],
"sameAssignee": true, "operator": "==", "value": 0 }
],
"actions": [
{ "type": "moveTicketStatus", "to": "InProgress" },
{ "type": "runAgent", "agent": "{assignee}", "model": "claude-sonnet-4-6" },
{ "type": "commitAgentMemory", "agent": "{assignee}" }
]
}
La condition ticketCountInColumn == 0 garantit l'absence de parallélisme non contrôlé : un agent ne démarre pas un nouveau ticket tant qu'il en a un en cours. La dernière action, commitAgentMemory, persiste automatiquement la mémoire de l'agent après chaque run — c'est la clé de la capitalisation.
La mémoire comme outil de progression
Là où la plupart des setups d'agents IA restent stateless, memory.md introduit un état persistant structuré. Chaque agent maintient un fichier de leçons avec un compteur [+N] qui trace le nombre de fois où chaque leçon a été réappliquée :
## API / tooling [+5]
- curl on Windows mangles UTF-8 in JSON bodies.
Use python3 urllib.request instead. [+2]
- PR creation: gh not available;
az repos pr create has permission errors. [+2]
## SVG inline in Markdown [+3]
- NEVER use <marker> + marker-end="url(#id)" in inline SVGs. [+3]
- Draw arrowheads as explicit <polygon> elements.
Le compteur remplit deux fonctions : il indique quelles leçons ont de la valeur (elles reviennent), et il guide la consolidation — quand une entrée atteint [5+], elle migre vers SKILL.md comme règle stable. Les entrées à [0] sont supprimées.
Cette distinction entre SKILL.md (règles stables, rarement modifiées) et memory.md (apprentissages actifs, mis à jour à chaque run) est structurelle. Elle empêche la mémoire de devenir un fourre-tout et force une discipline sur ce qui mérite d'être retenu.
Capitalisation cross-projet
Les agents apprennent de leurs erreurs — un agent qui bute sur un problème ne le rencontre plus jamais grâce à memory.md. Mais le vrai changement d'échelle, c'est quand les projets commencent à partager des capacités entières.
Génération d'images mutualisée
Un content-writer sur Bloomii a besoin d'une illustration. Un content-writer sur Ekioo a besoin d'une cover. Aucun des deux ne sait comment fonctionne gpt-image-2, aucun ne gère de clé API, aucun ne se soucie du rate limiting.
Un seul processeur tourne en cron toutes les 10 minutes dans le Workspace central. Les agents de n'importe quel projet soumettent une requête via image-enqueue.mjs, reçoivent un ID, et passent à autre chose. Le processeur gère la file, les pauses quand le quota est atteint, la reprise automatique. L'agent est notifié quand l'image est prête.
node C:/IA/Workspace/.agents/tools/image-enqueue.mjs \
--prompt "..." --output path/to/cover.webp \
--project bloomii --ticket 189
Un outil, un processeur, N projets consommateurs. L'ajout d'un sixième projet ne nécessite aucune configuration — juste un appel à image-enqueue.mjs.
Boîte mail centralisée — dispatch automatique
Tous les projets partagent une seule boîte mail, exposée via VizMail (serveur HTTP local, 40+ endpoints REST). Quand un mail arrive — retour client Kalceo, feedback lecteur Bloomii, contact Ekioo — il est automatiquement dispatché vers le projet concerné sous forme de ticket KittyClaw. L'agent approprié le traite sans intervention humaine.
Le résultat : une seule boîte mail à surveiller, zéro tri manuel, et chaque projet reçoit ses mails pertinents sous forme de tâches exploitables par les agents.
Branding X centralisé
Quatre projets alimentent un seul compte X (@LainAgent_AI). Chaque projet a son propre outil de publication (x-post-tweet.mjs), mais la stratégie éditoriale vit dans un fichier unique — x-strategy.md — dans le Workspace central : piliers de contenu, voix, règles d'engagement.
Un community-manager rédige, lain valide. Pas de fragmentation d'audience entre quatre comptes fantômes. Un seul compte qui accumule de l'autorité, alimenté par quatre sources de contenu différentes.
Knowledge base hub-and-spoke
Le Workspace central fournit l'infrastructure partagée : documentation des API (KittyClaw, Brevo, Chrome CDP), credentials centralisées, outils CLI. Chaque projet maintient sa propre base de connaissance domaine — réglementation BTP et douleurs artisan pour Kalceo, recherche par pilier éditorial et packs de distribution pour Bloomii.
Un agent Kalceo qui envoie une newsletter et un agent Bloomii qui programme un post LinkedIn utilisent le même token Brevo, la même documentation, les mêmes patterns d'appel — sans savoir que l'autre existe. La connaissance infrastructure est écrite une fois, consommée partout.
Cadence comme signal de santé
Trente à cinquante tickets traités par semaine sur l'ensemble des projets. Ce chiffre n'est pas un objectif de productivité — c'est un indicateur de santé du système.
Quand la colonne Todo d'un projet accumule sans être drainée, le signal est clair : le backlog est mal priorisé, ou le projet manque d'agents adaptés pour les tâches en attente. La cadence hebdomadaire rend ce déséquilibre visible immédiatement.
L'agent evaluator calcule des scores après chaque ticket fermé : first-pass success rate, feedback compliance, delivery quality. Ces métriques mesurent si la capitalisation fonctionne — un taux de first-pass success en hausse indique que les agents s'améliorent run après run. Un taux qui stagne signale une mémoire qui ne s'alimente plus.
Un agent qui ne tourne pas régulièrement n'accumule pas de mémoire exploitable : il repart à zéro, refait les mêmes erreurs, redemande les mêmes clarifications. La régularité n'est pas une discipline de publication — c'est la condition pour que le système apprenne.
Conclusion
L'infrastructure tient en quatre fichiers par agent : preamble.md, automations.json, SKILL.md, memory.md. Ce qui la rend efficace, c'est la discipline d'alimentation : committer la mémoire après chaque run (l'action commitAgentMemory le fait automatiquement), supprimer les entrées à [0], promouvoir les leçons à [5+] vers SKILL.md.
La seule règle qui compte : ne jamais rater deux semaines de suite. Une semaine calme ne brise pas la cadence. Deux semaines brisent la mémoire des agents, la cohérence des projets, et le signal SEO.
Régularité d'abord. Volume ensuite.