
Un dashboard, ça a deux coûts cachés : le créer et le maintenir. La plupart des outils résolvent le premier (un assistant génère les requêtes SQL), puis laissent tomber le second (les données vieillissent, personne ne rafraîchit). KittyClaw a une approche différente, et elle tient en trois phrases :
Le LLM écrit la tuile une fois, en chat. Le refresh s'exécute périodiquement sans aucun token LLM, via un script shell ou PowerShell. Et l'output.md généré sert à la fois à l'humain et aux agents qui surveillent le projet.
C'est cette triple économie (coût initial minimal, opération gratuite, boucle fermée) que je veux décrire ici.
Le primitif .dashboard/<slug>/
Chaque tuile est un dossier dans le dépôt :
.dashboard/
ca-mensuel/
tile.yaml ← template, refresh, prompt, titre
script.ps1 ← collecte les données (optionnel)
output.json ← données rendues par le dashboard
health/
tile.yaml
script.ps1 ← collecte les métriques projet
data.json ← produit par script.ps1
output.md ← généré par LLM à partir de data.json
Le tile.yaml déclare trois choses :
template: kpi # parmi : kpi, kpi-grid, donut, bar-chart,
# sparkline, progress, heatmap,
# status-grid, gauge, leaderboard,
# table, timeline, markdown, mermaid, image
title: CA mensuel
refresh: 86400 # en secondes. 0 = jamais auto-rafraîchi
Quand le refresh se déclenche :
- KittyClaw exécute
script.*si présent → produitdata.json - Si la tuile a un
prompt, KittyClaw appelle le LLM avecdata.jsonen contexte → écritoutput.jsonououtput.md - Si la tuile n'a pas de prompt,
output.*est lu directement tel quel
La deuxième étape est la seule qui consomme des tokens, et seulement sur les tuiles markdown qui synthétisent de la donnée brute. Les tuiles kpi, bar-chart, sparkline et compagnie rendent output.json côté serveur : zéro LLM à l'exécution.
Galerie de tuiles : projet BrewCo
Pour illustrer l'étendue des templates sans screenshot d'un vrai projet en production (les chiffres réels ne sont pas publics), j'ai créé BrewCo : une chaîne fictive de 12 coffee shops. Onze tuiles, sept templates différents, toutes alimentées par du JSON réaliste.
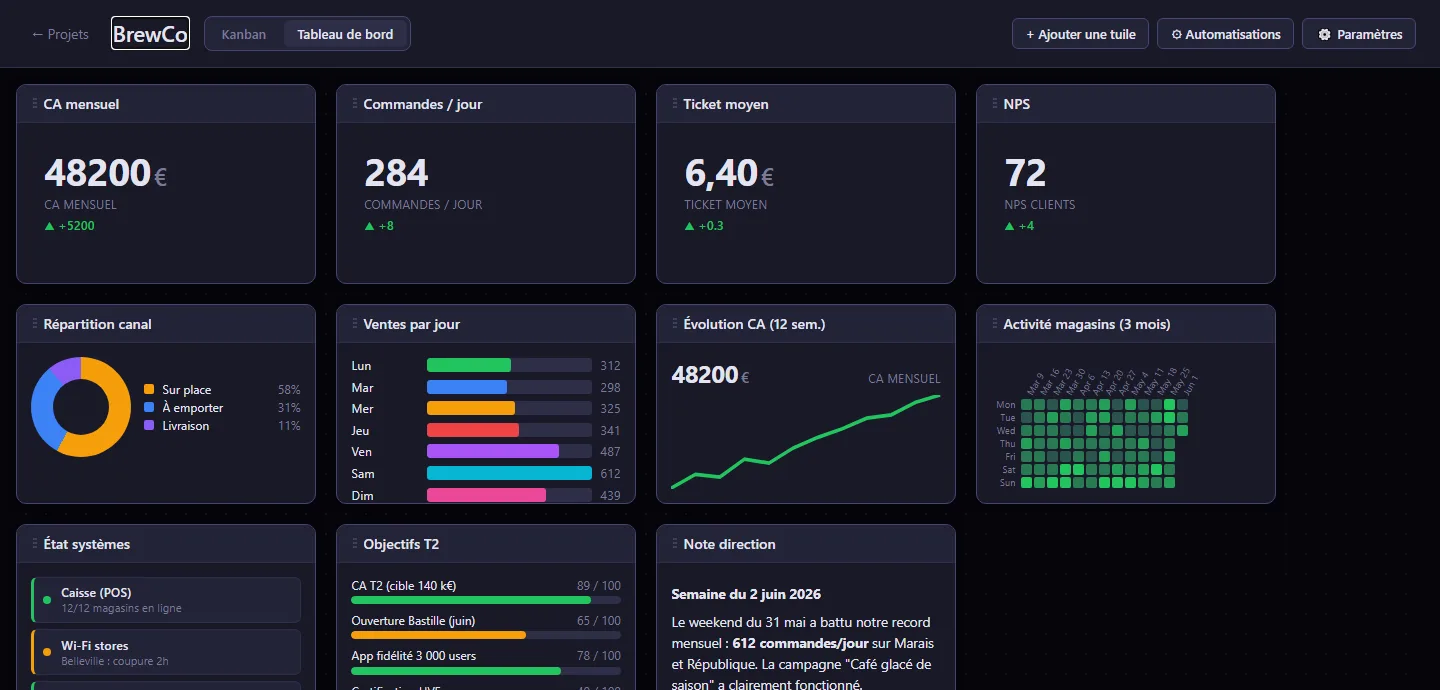
Première rangée : scan rapide. Quatre tuiles kpi : CA mensuel, commandes/jour, ticket moyen, NPS. Chacune est un output.json de cinq champs (value, label, unit, delta, trend). Le delta et la flèche de tendance sont rendus automatiquement.
Deuxième rangée : lecture analytique. Un donut (répartition canal : sur place 58 %, à emporter 31 %, livraison 11 %), un bar-chart (ventes par jour de la semaine, le samedi à 612 saute aux yeux instantanément), une sparkline (évolution du CA sur 12 semaines), et une heatmap de style GitHub Calendar montrant l'activité des 90 derniers jours.
Troisième rangée : état et contexte. Un status-grid (6 systèmes avec statuts ok/warn/err, le Wi-Fi d'un magasin est en warn), des progress bars pour les objectifs T2, et une tuile markdown pour la note hebdomadaire de direction.
Chaque template a son propre schéma JSON, documenté dans l'interface : le chat IA de création de tuile injecte automatiquement le bon schéma dans son prompt.
La boucle fermée : Lain lit output.md
Ce qui rend ce primitif particulièrement puissant, c'est que les output.md des tuiles analytiques deviennent naturellement un input pour d'autres agents.
Sur le projet ekioo, la tuile health produit chaque jour un output.md qui croise métriques tickets (vélocité, blocages, tickets stagnants), données trafic Umami et signaux SEO Search Console. Ce fichier est lu par Lain, l'agent CEO qui passe en revue le board toutes les heures :
# .dashboard/health/tile.yaml
template: markdown
refresh: 86400
prompt: 'Read the JSON at .dashboard/health/data.json, which contains
ticket metrics, roadmap goals, and optionally umami (traffic) and
gsc (SEO) data. Cross-reference all signals. Format: Diagnostic
(3 phrases), Risques (2 bullets), Action de la semaine (1 bullet).
Be opinionated. Output ONLY the raw markdown.'
Lain ne poll pas l'API KittyClaw à 30 reprises pour reconstituer un état global. Il lit health/output.md, un document déjà synthétisé, à jour, en langage naturel, et décide sur cette base si un ticket doit être escaladé ou si un sujet SEO mérite une action immédiate. Un seul appel LLM consomme un contexte déjà traité.
C'est la même logique que les systèmes de cache dans une architecture backend : on calcule une fois, on sert N fois.
Le dashboard n'est pas réservé aux projets tech
BrewCo n'est pas un projet de dev. C'est une chaîne de café. Et les tuiles fonctionnent exactement pareil : un script PowerShell qui lit un CSV d'export de caisse, produit un data.json, et le dashboard affiche les KPI du weekend.
Le primitif (tile.yaml + script.* + output.*) est suffisamment générique pour monitorer des métriques business, des campagnes marketing, ou des opérations physiques. La seule contrainte est que les données soient lisibles par un script. Si elles le sont, le dashboard peut les afficher.
C'est délibéré. KittyClaw est un outil de gestion de projet et d'orchestration d'agents, pas un outil BI SaaS. Le dashboard est une couche d'observabilité, pas une fin en soi.
Observabilité entre humain et agents
Ce qui m'intéresse dans cette architecture, c'est qu'elle résout un problème de coordination que les systèmes agentiques créent : l'humain et les agents ont besoin de voir la même réalité, mais à des granularités différentes.
L'humain veut une vue d'ensemble : quelques chiffres, une tendance, une alerte. L'agent veut une entrée structurée qu'il peut raisonner. Le output.md de la tuile health est les deux à la fois : lisible par un humain en 30 secondes, parsable par un agent en un seul appel.
Ce n'est pas une révolution d'infrastructure. C'est un fichier texte régénéré chaque nuit. Mais c'est exactement la bonne abstraction pour la couche entre l'humain qui pilote et les agents qui exécutent.