
Un tableau dans une fiche Kalceo, propre et bien formaté. Ligne : "aide exceptionnelle apprenti, niveaux 5 à 7 : 5 000 €". Citation : service-public.fr. Un artisan BTP qui consulte cette fiche monte son calcul de rentabilité, évalue si embaucher un apprenti est viable, prend sa décision.
Sauf que le vrai barème, vérifié le 9 mars 2026 sur la fiche F23556 de service-public.fr, est :
- 4 500 € pour le niveau 5 (BTS, DUT, BUT)
- 2 000 € pour les niveaux 6 et 7 (Licence, Master)
Pas 5 000 €. L'écart peut faire la différence entre "je recrute un apprenti diplômé Bac+5" et "je ne recrute pas". La fiche a été corrigée avant publication. Mais elle n'aurait jamais dû contenir cette erreur.
Ce n'est pas un cas isolé. C'est le problème structurel des agents LLM : ils produisent du texte d'apparence autoritaire sur des sujets qu'ils maîtrisent partiellement. Ils n'improvisent pas, ils synthétisent. Et dans cette synthèse, ils interpolent, arrondissent, confondent, avec une précision qui désarme la méfiance.
Trois projets en production nourrissent cet article : Bloomii, un média de journalisme constructif sur les alternatives sociales et environnementales ; Kalceo, un SaaS B2B réglementaire pour les artisans du bâtiment ; et Ekioo, le projet R&D fleet d'agents derrière cet article. Tous trois tournent sur KittyClaw, un orchestrateur kanban pour agents IA.
Le problème n'est pas que le modèle
Les garde-fous intégrés s'améliorent. Les modèles aussi. Mais en 2026, ça ne suffit pas encore. La qualité varie d'un run à l'autre, d'un sujet à l'autre, sans raison apparente. Un modèle qui produit un article irréprochable sur l'ESS (économie sociale et solidaire) peut, le lendemain, sortir une statistique fiscale approximative sur le même sujet.
« Toute production par un LLM est sujette aux hallucinations : même si les modèles s'améliorent et que les systèmes agentiques intègrent des garde-fous built-in, aujourd'hui cela n'est pas encore suffisant. Certains modèles bâclent le travail. La raison est un peu obscure parfois — d'une journée à l'autre ou d'un sujet à l'autre, le modèle est parfois plus pertinent. »
La réponse n'est pas d'attendre de meilleurs modèles. C'est une réponse architecturale.
« C'est pourquoi il faut découpler les responsabilités et créer des agents adversariaux qui sont exécutés séparément de la production de contenu elle-même. Chaque agent a ses skills, son objectif, sa mémoire, son contexte... c'est ainsi qu'on crée des boucles de contrôle saines et fiables. »
Un agent produit. Un autre vérifie, séparément, avec un contexte d'exécution distinct et un objectif opposé : chercher activement ce qui ne tient pas. C'est la base du pattern adversarial. Ce n'est pas du contrôle qualité ajouté après coup, c'est une décision d'architecture.
Acte 1 : la bascule (17 mai 2026, Bloomii)
Bloomii est un média sur les alternatives sociales et environnementales. Chaque chiffre publié engage la crédibilité du projet : si un article affirme que l'ESS représente 10% de l'emploi français alors qu'elle représente 10% du PIB, on perd la confiance de lecteurs qui, eux, connaissent le sujet.
Le premier rapport du fact-checker, daté du 2 mai 2026, bloque un article sur l'agriculture régénérative. Cause : une statistique CIAT censée montrer "78% de rentabilité supérieure et 176% de ROI moyen sur 4 fermes". La page citée existe, répond HTTP 200, parle bien d'agriculture régénérative. Mais le chiffre exact n'est nulle part dans le texte. Le fact-checker ne peut pas valider. Il bloque.
À cette date, le fact-check est encore ponctuel. Quinze jours plus tard, tout change.
Le 17 mai, dans le dépôt Bloomii :
feat(agents): enforce fact-check on all channels — brèves, X threads, newsletter
Avant : fact-check à la demande. Après : passage obligatoire sur tout canal sortant. Brèves quotidiennes, threads X, newsletter, articles longs, atlas d'initiatives. Plus aucun contenu ne peut passer en Review sans être passé par le fact-checker.
Ce qui déclenche la décision :
« La relecture des articles a montré des coquilles de génération qui n'étaient pas acceptables pour un média d'information sérieux. En ligne, on engage sa crédibilité, et celle-ci se perd très vite. C'est une question de sérieux et c'est un argument démarquant face aux autres médias approximatifs qui relayent des informations non vérifiées. »
Les résultats sont immédiats. Exemple concret : le script d'une vidéo sur l'ESS France affirme que le secteur représente "dix pour cent de l'emploi français". La Direction générale du Trésor dit l'inverse : 10% du PIB, et 13,7% de l'emploi privé. Ce n'est pas la même chose. Script corrigé avant publication.
Sur les threads X traitant des articles 7 à 11 de propositions de loi, même pattern : chiffres de participation, dates de sessions, résultats de votes. Tout passe par le fact-checker. L'assemblée citoyenne irlandaise sur la biodiversité (2022-2023) : 99 membres tirés au sort, 83% favorables à un référendum constitutionnel, rapport remis au Parlement le 5 avril 2023. Vérifié contre citizensassembly.ie.
Sur les 48 rapports Bloomii accumulés entre le 2 mai et le 11 juin 2026, une majorité se conclut en PASS avec des corrections appliquées. Le volume en dit plus que le détail : un sujet par rapport, une à trois corrections par rapport en moyenne, sur des sujets allant de la coopérative Mondragon aux budgets participatifs de Porto Alegre, en passant par les fiches Atlas d'initiatives locales.
Acte 2 : le source-registry (30 mai 2026)
Deux semaines après la bascule, un problème d'efficacité apparaît. Le fact-checker et le source-researcher travaillent souvent sur les mêmes sources. L'un cherche et valide les URLs, l'autre ouvre et confirme les claims. Deux agents, souvent les mêmes domaines, double consommation de tokens.
Le 30 mai, dans le dépôt Bloomii :
chore: add shared source-registry and wire it into fact-checker/source-researcher
Le registre de sources est un fichier partagé entre les deux agents : .agents/knowledge/source-registry.md. Il référence les domaines connus, leur statut d'accès (HTTP 200, 403 anti-bot, timeout), les fallbacks validés, et les vérifications déjà effectuées. Par exemple, certains éditeurs scientifiques bloquent systématiquement les requêtes automatisées. Le registre documente la source de substitution validée. Plus aucun agent n'essaie, ne découvre le blocage, ne cherche une alternative par tâtonnement. Il consulte le registre et applique directement.
Sur la décision de fusionner cette ressource :
« Le travail était fait deux fois par deux agents différents. Fusionner cette ressource ne remettait pas en cause leur efficacité et objectivité respective, mais contribuait à alimenter une base commune et donc à économiser des tokens. Et cela permettait également d'avoir une traçabilité des sources, pas juste un travail temporaire et oublié. »
Trois bénéfices distincts :
Économie de tokens. Les vérifications sont mises en cache. Un domaine testé une fois n'est plus re-testé sur chaque article. À l'échelle de 48 rapports, la somme est substantielle.
Traçabilité durable. Les rapports de vérification restent dans le dépôt. Un chiffre vérifié aujourd'hui n'est pas perdu après le run. Il est consultable, auditable, disponible pour le prochain article sur le même sujet.
Indépendance préservée. Les deux agents partagent un registre de sources, pas un jugement. Le source-researcher et le fact-checker continuent à travailler séparément sur leurs objectifs respectifs. C'est précisément cette séparation qui crée la valeur adversariale. Le fact-checker n'a pas accès au raisonnement du source-researcher, et vice versa.
Un registre commun ne dilue pas le contrôle : il l'optimise.
Workflow : du ticket au verdict
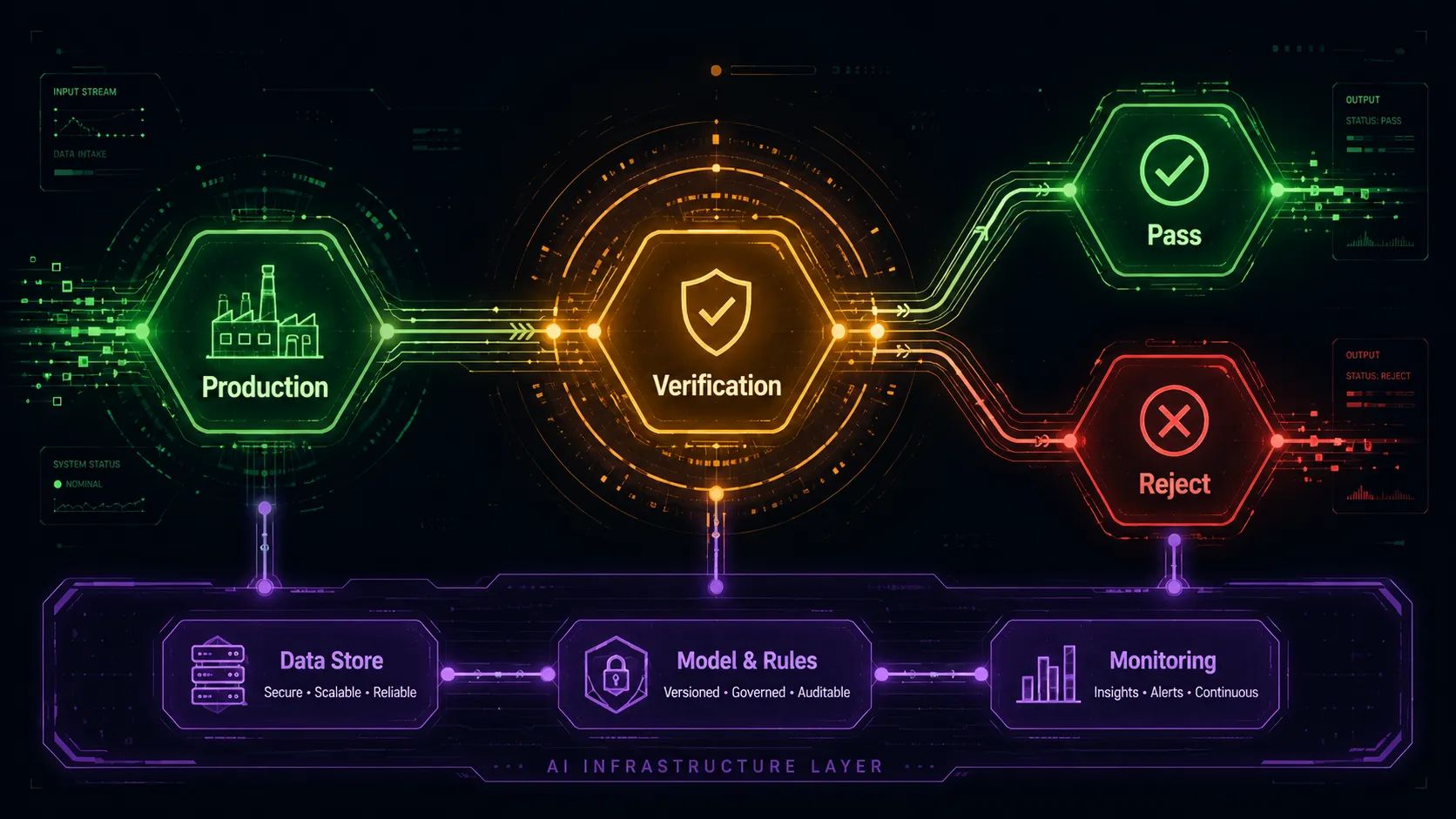
Acte 3 : l'extension (juin 2026)
Le pattern sort des articles de fond. Il s'applique à tout contenu sortant, quelle que soit la surface.
Kalceo : contenu réglementaire B2B
Kalceo produit des fiches techniques pour artisans BTP : TVA sur travaux, aides à l'apprentissage, facturation électronique, gestion des impayés. Le risque n'est pas éditorial, il est juridique et financier. Un artisan qui suit une information erronée sur les aides à l'apprentissage ne rate pas un article de blog, il rate une aide de 2 500 €.
Le catch sur les aides apprenti détaillé en ouverture est le cas d'école. Mais un autre rapport, sur les impayés artisans, illustre un autre type d'erreur, plus subtil.
Le témoignage d'ouverture décrivait "Stéphane, peintre à Nice, qui attendait un client lui devant 4 000 €". La source vérifiée, une plateforme de recouvrement de créances en ligne (GCollect), disait "Stéphane, artisan à Nice". Pas de profession. Pas de montant cité. Le passage était une reconstruction du rédacteur à partir d'un contexte insuffisant. Supprimé. Six corrections au total dans ce rapport : profession inventée, montant inventé, attribution de statistiques au mauvais organisme (FFB/Altares → EY/Altares/Banque de France), liens génériques vers des pages d'accueil remplacés par les URLs d'articles sources.
12 rapports Kalceo sur 3 semaines (2026-04-16 au 2026-05-06). Sujets : TVA travaux, dévis bâtiment, plateforme e-facture (identification d'une terminologie incorrecte sur le Portail Public de Facturation (PPF) et son rapport à Chorus Pro, d'un chiffre de 112 plateformes de dématérialisation partenaires (PDP) dépassé, d'une statistique CAPEB non vérifiable), impayés, aides et subventions, sanctions facturation électronique.
Ekioo : du projet à lui-même
Ekioo applique le même fact-check à ses propres fiches projet et drafts sociaux.
Côté fiches projet : la page VizMail annonçait 43 fonctionnalités. Après vérification directe de l'API (GET /api/skill), le compte exact est 38. Cinq fonctionnalités annoncées n'existaient pas. Auto-signalement : l'article parlait d'un produit du même écosystème, et le chiffre était faux.
Côté drafts sociaux : les drafts LinkedIn et X générés pour le KPI dashboard KittyClaw contenaient deux erreurs. "Chaque matin" dans un tweet : l'article source précise que la revue est toutes les heures, pas chaque matin. "11 templates" : l'article dit 11 tuiles et 7 templates distincts. Six lignes modifiées.
C'est le dernier filtre avant publication. Pas seulement un vérificateur de chiffres : le fact-checker peut valider le hook d'un short YouTube, vérifier l'objectivité et le ton d'un thread, détecter un biais dans l'angle choisi. Le projet AccountBuildUp pousse ce pattern plus loin : un agent vérifie la pertinence thématique de chaque post généré par rapport à un corpus de textes de référence. image-factory et video-factory (les pipelines de production d'images et de vidéos mis en place dans KittyClaw pour les différents projets) incluent eux aussi des vérifications systématiques avant livraison : cohérence visuelle, respect de l'identité graphique, conformité aux critères éditoriaux. La validation n'est pas une étape à part : c'est une couche intégrée à chaque pipeline de production.
Le pattern généralisable
En huit semaines, 61 rapports de vérification sur trois projets aux profils radicalement différents : un média sur les alternatives sociales (sujets idéologiquement sensibles), un SaaS B2B réglementaire (sujets légalement sensibles), et un blog technique sur la construction de ce même système.
Le pattern qui émerge n'est pas spécifique au contenu éditorial.
Un claim-checker sur les commentaires de code : une docstring qui affirme que la fonction retourne X alors qu'elle retourne Y est une hallucination documentaire. Le code change, la documentation reste. Un agent adversarial lit le code et la doc, et signale les divergences.
Un fact-checker de landing page : les claims commerciaux sont un terrain d'hallucination classique. VizMail 43→38 en est déjà un exemple. L'agent qui rédige la page de vente et l'agent qui compte les fonctionnalités réelles ne doivent pas être le même.
Un audit de prémisses stratégiques : avant d'engager une décision chiffrée, vérifier que les chiffres qui la fondent sont exacts. Même logique, appliquée en amont.
Dans chacun de ces cas, le principe est identique : un agent produit, un autre vérifie séparément, avec son propre contexte, son propre objectif. Ce n'est pas de la redondance. C'est une boucle de contrôle.
Le scaling IA n'est viable que si la vérification l'est aussi
Scaler la création de contenu avec des agents IA résout un problème tout en en créant un autre. Si la production décuple mais que la validation reste manuelle, le goulot d'étranglement se déplace de la production vers la revue humaine.
« Si l'IA est très utilisée pour scaler la création de contenu, les humains eux deviennent un goulot d'étranglement s'il faut vérifier l'ensemble à chaque fois. C'est pourquoi nous avons besoin de pipelines de production avec lesquels nous pouvons être en confiance. Le rôle des fact-checkers, gardiens, judges, validators, etc. permet de créer cette confiance. Et les retours permettent aux agents producteurs de contenu de s'améliorer afin de converger vers des contenus plus qualitatifs et de limiter les itérations. »
Le fact-checker n'est pas qu'un filtre : c'est aussi un mécanisme d'apprentissage. Chaque rapport documenté (claim identifié, correction appliquée, source primaire) devient un signal pour les agents producteurs. La mémoire s'ajuste, le skill évolue, les mêmes erreurs se reproduisent de moins en moins. Ce n'est pas un coût récurrent : c'est un investissement qui diminue à mesure que le pipeline mûrit.
Sans validation automatisée, l'IA ne scale pas vraiment. Elle se contente de déplacer le goulot.
Ce qu'on attendrait d'un humain
Une rédaction professionnelle humaine n'enverrait pas un article sans relecture, sans vérification des sources, sans validation du style. Un juriste ne livrerait pas un document sans vérifier les références législatives. Un directeur artistique ne validerait pas un visuel sans vérification de conformité à la charte.
Ce contrôle qualité n'est pas une mesure exceptionnelle. C'est une pratique standard dans tout processus de production sérieux.
Le fact-checker est l'équivalent automatisé de ce rôle. Il n'est pas là parce que l'IA est particulièrement peu fiable : il est là parce qu'aucun système de production, humain ou artificiel, ne devrait publier sans validation. La différence : il s'exécute à chaque ticket, sans exception, sans fatigue, avec un rapport documenté.
La crédibilité comme infrastructure
On peut objecter que le sourcing systématique sur sources primaires produit du contenu tiède, vidé de son souffle analytique. La réponse est directe : "Il faut citer la source juste, éviter les formulations tièdes." Sourcé ne signifie pas plat. La contrainte de vérification n'interdit pas l'angle assertif, la mise en tension des chiffres, le choix éditorial.
Ce qu'elle interdit, c'est de publier "5 000 €" quand le barème légal est "4 500 €". Ce qu'elle interdit, c'est d'attribuer à Stéphane un métier qu'il n'a pas et un montant qui n'est pas dans la source. Ce qu'elle interdit, c'est de laisser passer "chaque matin" quand l'article dit "toutes les heures".
Un média sérieux n'est pas celui qui publie le plus, ni le plus vite. C'est celui qui peut défendre chaque chiffre, chaque date, chaque claim dans n'importe quel article, à n'importe quel moment. Institutionnaliser le fact-check, c'est s'interdire de devenir un de ces relais approximatifs dont la crédibilité se rogne article par article.
La crédibilité n'est pas un style. C'est une infrastructure.